- クラウド技術
S3 Vectors×Bedrock Knowledge Basesで構築する社内ナレッジ検索システム
- #AWS
- #AI

はじめに
【エンジニア募集中】フルリモート可◎、売上/従業員数9年連続UP、平均残業8時間、有給取得率90%、年休124日以上 etc. 詳細はこちらから>
S3 Vectorsは、ベクトルデータの保存・クエリをネイティブにサポートする初のクラウドストレージです。Amazon Bedrock Knowledge Basesと統合することで、社内ドキュメントのナレッジ検索(RAG)システムを低コストかつ簡単に構築できます。
前提条件
- AWSアカウントとIAM権限(S3 Vectors、Bedrock両方へのアクセス)
- 対応リージョン(東京リージョンも利用可能)
- ナレッジベース用のソースドキュメント(最大50MB)
ソースドキュメントの対応ファイル形式
|
形式 |
拡張機能 |
|
プレーンテキスト (ASCII のみ) |
.txt |
|
マークダウン |
.md |
|
HyperText マークアップ言語 |
.html |
|
Microsoft Word ドキュメント |
.doc/.docx |
|
カンマ区切り値 |
.csv |
|
Microsoft Excel スプレッドシート |
.xls/.xlsx |
|
Portable Document Format |
|
構築手順
画面レイアウトは 2026/01/24時点のものです
Step 1: ソースドキュメントの準備
- S3を開く。
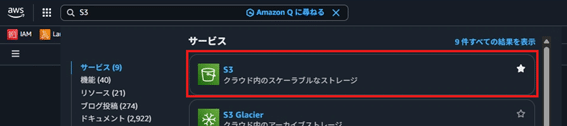
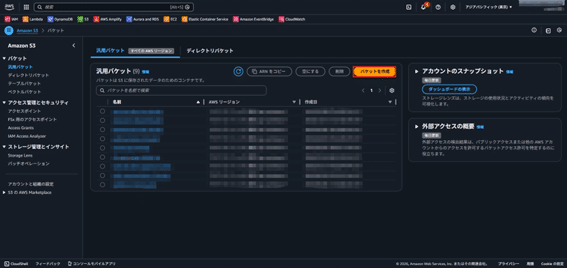
- S3コンソールで「バケットを作成」をクリック。
- バケット名を入力し、その他の設定項目は変更せずにそのまま進む。
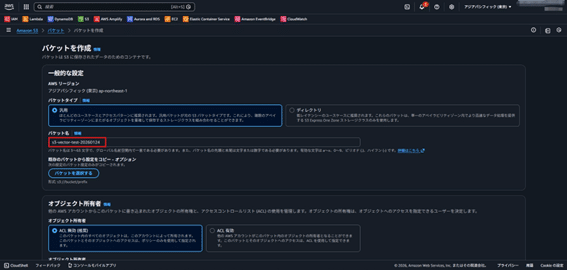
- 「バケットを作成」をクリック。
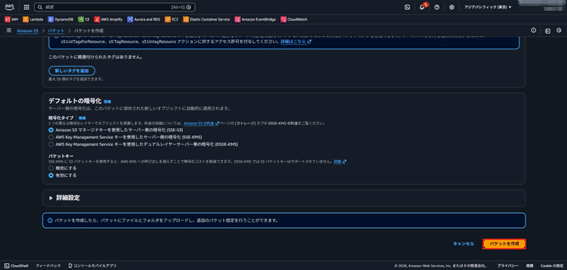
- 作成したバケットを開き、ドキュメントを3点ほどアップロード。
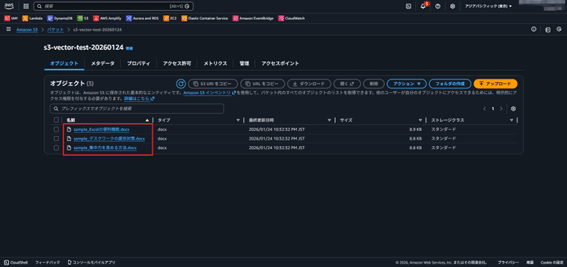
・アップロードファイル1点目 – sample_Excelの便利機能.docx

・アップロードファイル2点目 – sample_デスクワークの疲労対策.docx

・アップロードファイル3点目 – sample_集中力を高める方法.docx

Step 2: Bedrock Knowledge Basesの作成
- Amazon Bedrockを開く。
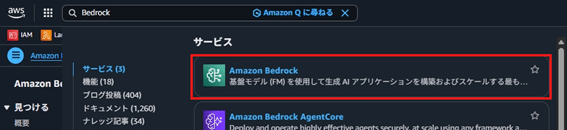
- Bedrockコンソールで「ナレッジベース」→「作成」を選択。
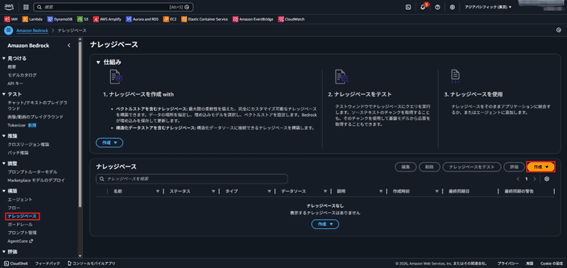
- 「ベクトルストアを含むナレッジベース」を選択。
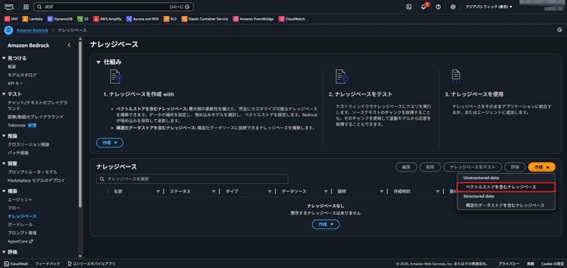
- データソースでS3を選択し、次へ。その他の設定項目は変更せずにそのまま進む。
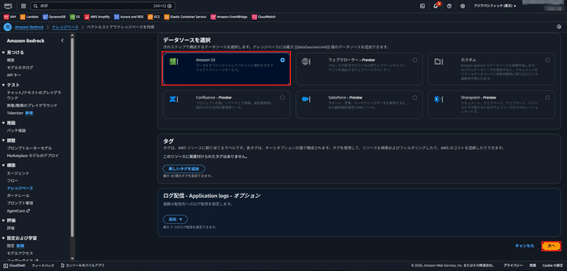
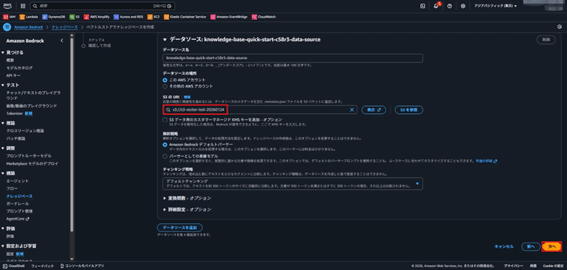
- S3 の URI:参照でStep 1のS3バケットを指定し、次へ。その他の設定項目は変更せずにそのまま進む。
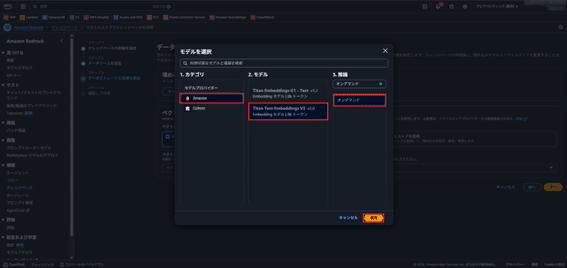
- 埋め込みモデルを選択(Amazon Titan Text Embeddings等)。
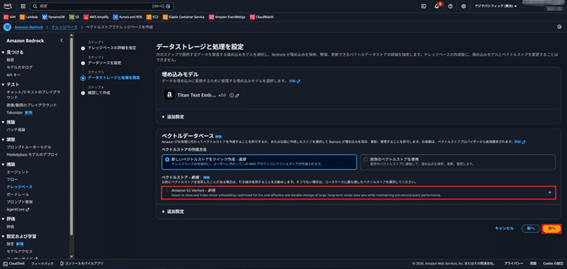
- ベクトルデータベースにあるベクトルデータベースでS3 Vectorsを選択し、次へ。
- 「ナレッジベースを作成」をクリック。
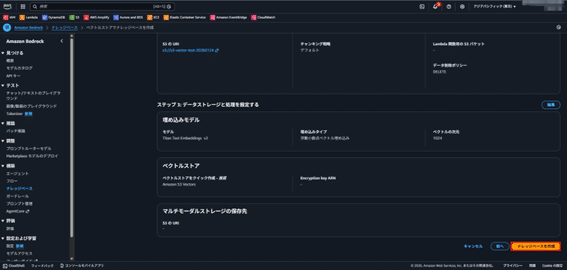
Step 3: データソースの同期
- 作成したナレッジベースを選択。
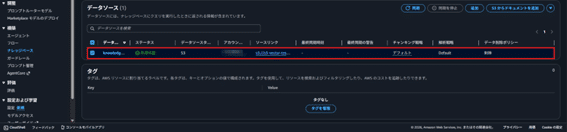
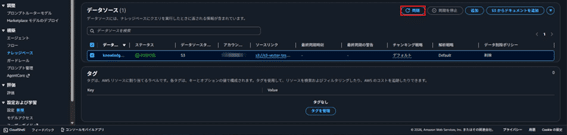
- データソースの概要セクションで「同期」をクリック。この時点でベクトル化を行い、テキストの意味検索が可能になります。
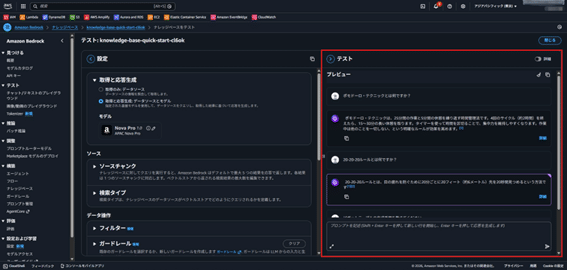
Step 4: ナレッジ検索のテスト
- ナレッジベース画面で「ナレッジベースをテスト」を選択。

- 「取得と応答生成」にある「取得と応答生成」を選択し、モデルを選択(Amazon Nove Pro 1.0等)。
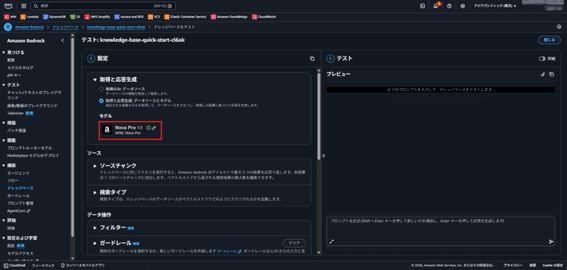
- 質問を入力してナレッジ検索の動作を確認。
まとめ
S3 VectorsとBedrock Knowledge Basesを組み合わせることで、インフラ管理の負担を極限まで減らし、コストを抑えたナレッジ検索(RAG)システムを構築できます。
参考:
Amazon Bedrock ナレッジベースデータの前提条件
https://docs.aws.amazon.com/ja_jp/bedrock/latest/userguide/knowledge-base-ds.html
【エンジニア募集中】フルリモートも◎(リモート率85.7%)、平均残業8時間、年休124日以上、有給取得率90% etc. 詳細はこちらから>





